

首先,很感谢很多品牌方因为看过我们的公众号,或经客户推荐找到我们,邀请我们参与 GEO 项目投标。
这本身是对我们专业能力的一种认可,我们也非常珍惜每一次沟通机会。
但坦白说,有些标书看完之后,我们确实只能选择婉拒。
不是不想做,而是上面的很多要求——臣妾真的做不到。
换个角度想,大部分品牌方此前并没有真正做过 GEO 优化,那这些看似“专业”的 KPI 是怎么写进标书里的?
答案可能有点扎心:很多品牌方,早就在资料筛选和需求制定阶段,被一些敢吹、敢画饼的服务商带偏了
今天,我们就从从业者角度,拆一拆 GEO 标书里的细节,看看很多品牌方是则怎么被带偏的。
(为了避免“福尔摩斯网友”根据标书细节去对号品牌,下面提到的数据部分并非来自某一份具体标书,而是综合多份标书内容后进行截取、整理,并做了脱敏处理。)
一、KPI设定不合理,服务商乱承诺
首先,最明显、最直接的就是KPI设定的不合理,大家可看下下面这组数据:

简单翻译一下:首推率低于 80%,或提及率低于 95%,就要扣掉一半费用,基本等同于不合格。
但从实际数据看,这个标准并不现实。对比我们服务过、且本身就是行业绝对头部的品牌(快消、家电等),首推率平均也只有 75% 左右,提及率平均不到90% (而且很难稳定)。
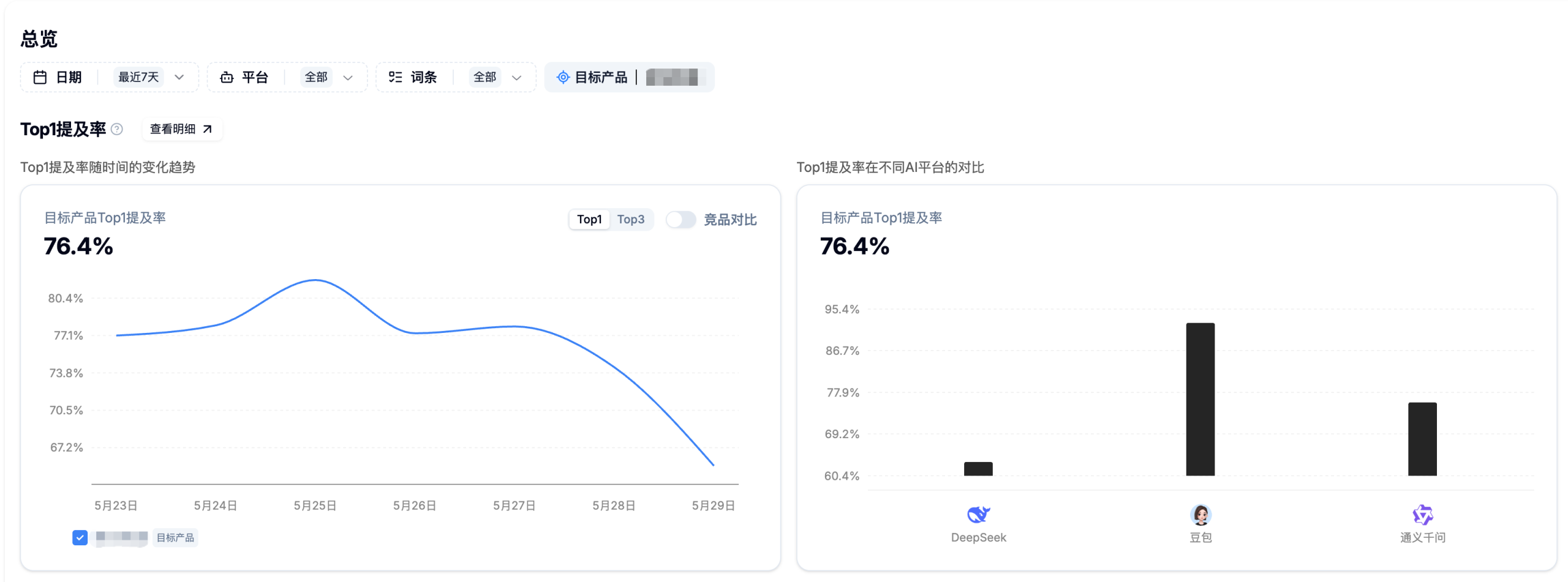
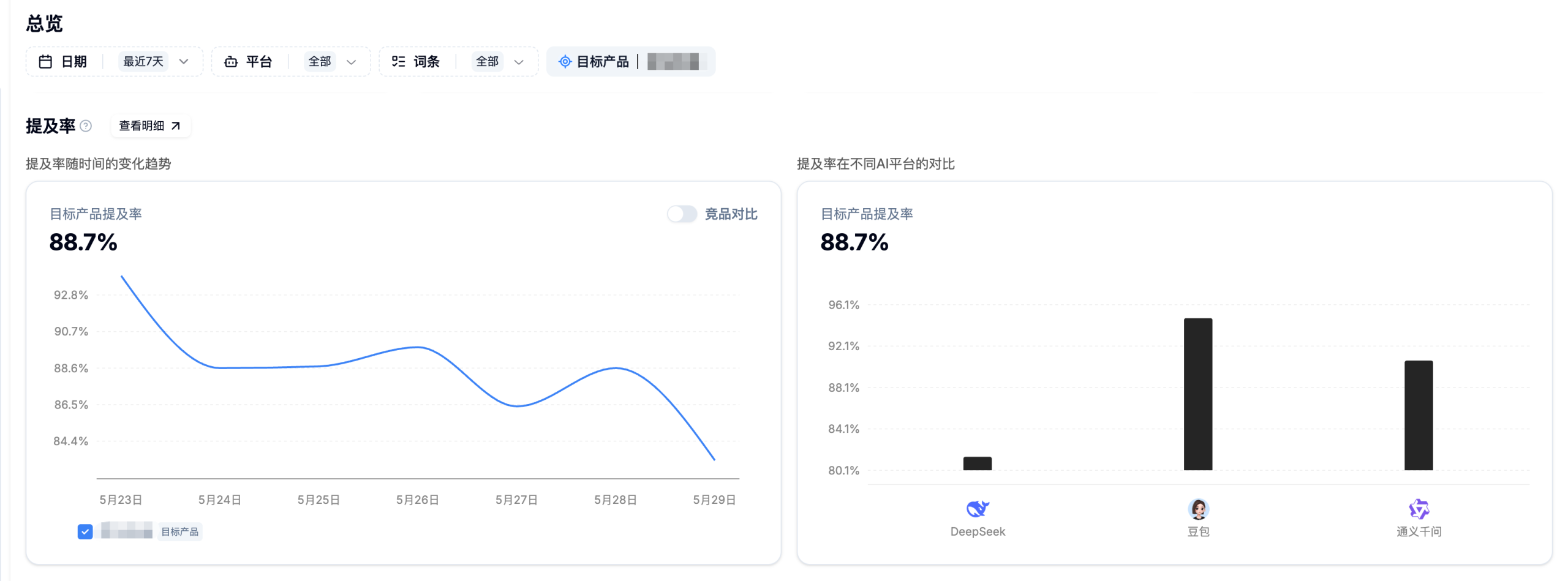
也就是说,连行业头部品牌经过长期优化后都未必能稳定达到,更别说很多提出这类要求的品牌,本身还不是行业绝对头部。
当然,我们不敢说我们做不到,这个世界上就没有人做得到。
但是任何事情总得符合最基本的规律,AI 的中立性和不稳定性就决定这个值的上限规律,这不是百度搜索卖广告,只要你钱出到第一名,你永远在第一名。
大家也可以自己做个实验:找一个你熟悉的行业,多问 AI 几次,看看有没有哪个品牌能 90% 稳定占据第一推荐位。
比如在各个模型里连续搜 10次“高端手机推荐”这类泛品词,你看看苹果的首推率能不能达到 90%?
估计最简单的实现的方式可能就是数据造假了,好奇具体怎么造假的可以跳转我们上篇文章《GEO服务商都不知道的造假方式!(服务商慎入)》
二、标书要求的数据校验:成本可达每月5万以上
标书里另一个离谱的地方,是关于“效果如何验证”的条款。
品牌方大概是听信了某些销售的洗脑,以为只要“查询次数足够多、IP 足够分散”,就能证明数据的真实性。比如某标书里的验收标准是这样的:

- 验证方式:选取 20 个核心品类词,使用 100 个分布在不同区域的真实 IP 账号进行查询验证。
- 查询频次:每日对上述词条进行多轮巡检,每天不低于2000次/天
- 覆盖平台:覆盖国内豆包、通义千问、DeepSeek等主流 AI 模型。
我们来算个账,20个词,每个查100次,就算3个 AI 平台,那么:
每日查询次数:20*100*3=6000次
按照目前行业里较常用的模拟用户在 AI 客户端进行搜索对话的方式来计算,一次问询背后会涉及服务器、电费、流量、账号、数据清洗等多项成本。综合摊算下来,单次查询成本大约在 0.3 元左右。
每月成本:0.3元*6000词*30天=54000元
一个月光查询成本就要 5.4 万,你敢信?很多品牌方整个 GEO 服务预算,都未必能超过 5 万。
更关键的是,这种高频消耗本身并没有太大意义。我们做过实际测试,同一天内针对同一个问题多次询问,结果差异并不明显。所以在实际项目中,我们通常建议客户:同一词条每天监测一次即可,最后看一个月的平均表现,反而更能反映品牌在 AI 回答里的真实位置。
三、设定跟竞品对比,还要求自己 100% 完胜
来看下标书中的 KPI:

翻译一下就是:只要用户问“我们品牌和竞品哪个好”,AI 就必须说我方更好,而且回答里只能有正面信息,不能出现任何负面内容。
但在不投毒、不搞灰色手段的前提下,我们从来不建议品牌通过踩竞品来做 GEO。品牌可以突出自己的真实优势,也可以在测评、对比类内容里做到“扬长避短”,把自己的优势讲清楚,把短板适度表达出来。越真实、越中立、越符合用户决策逻辑的内容,反而越容易被 AI 采纳。
所以这类 KPI 最大的问题在于:它不是要求 AI 客观对比,而是要求 AI 必须站队。
那问题来了,这个怎么实现?靠真实内容优化很难做到,难道靠投毒吗?
更何况,315 之后,行业已经开始整改。靠信息污染、恶意踩踏、批量投毒来影响 AI 回答的路子,迟早走不通。
写在最后
看完这些标书细节,我其实挺为品牌方惋惜的。
他们不是不想把 GEO 做好,恰恰相反,是太想在这个人人焦虑“被 AI 忽略”的时代里拿到结果。
但问题在于,行业标准还不清晰,技术认知也有盲区。很多品牌方听信了那些“拍胸口打包票”的伪 GEO 团队,把谎言当成了标准,最后写出了一份看似专业、实则逼着服务商造假的招标说明书。
品牌的 GEO 标书,反而在筛掉靠谱服务商
如何验收效果?-cover-qfey4m-890x664.png)
