

如果你最近一年开始认真研究 GEO(生成式引擎优化),很可能已经遇到一个让人不太舒服的现象:市面上的 GEO 监测工具越来越多,报表越来越漂亮,但你对这些数据的信任感却在下降。
你明明在后台看到「品牌可见度提升」「AI 提及率上涨」「覆盖问题数增加」,可当你自己真正站在一个普通用户的视角,去问一次豆包、DeepSeek、ChatGPT或 Gemini,得到的答案却完全对不上。
更让人困惑的是,这种“不对劲”往往说不清楚。因为从数据形式上看,一切都显得合理、完整、专业,甚至比传统 SEO 报告还要先进。
问题不在于你不懂 GEO,而在于:现在相当一部分所谓的 GEO 数据,本身就是在制造一种“看起来正确”的假象。
一、很多人不是做错了 GEO ,而是从第一天就被“假监测”带偏了
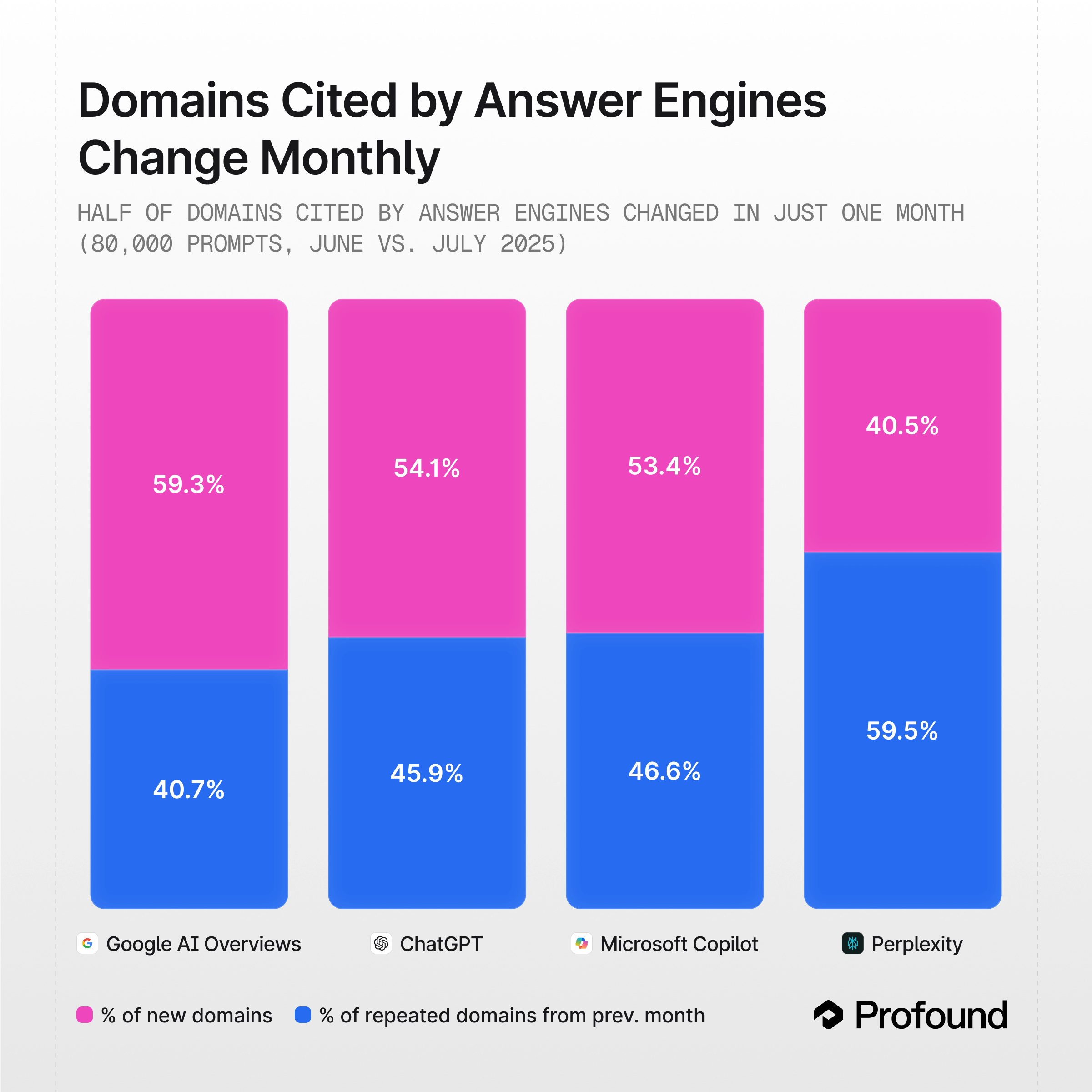
先说一个在实际咨询中反复出现的场景。不少团队在使用某些 GEO 监测方案后,会得到非常稳定、非常一致的结果:某些关键词始终能被“检测到”,品牌在 AI 回答中似乎持续出现,相关评分几乎没有大幅波动。
从传统 SEO 的经验来看,这反而让人安心——稳定意味着可控。但放在生成式 AI 的世界里,这种稳定本身就值得警惕。因为真实的 AI 搜索环境,本质上是高度动态的。
同一个问题,在不同时间、不同地区、不同用户上下文下,出现不同答案才是常态。如果一个监测系统长期给你输出几乎不波动、结构高度一致的结果,唯一合理的解释不是“模型终于稳定了”,而是你看到的并不是真实用户看到的那个世界。简单来说,因为绝大多数服务商为了省事,都在走 API 调用的捷径。
二、API 数据不是“不够好”,而是“根本不是一回事”
要理解当前 GEO 监测最大的分歧点,必须把一个问题说透:API 调用输出,和真实用户访问时看到的 AI 回答,是两个不同层级的东西。
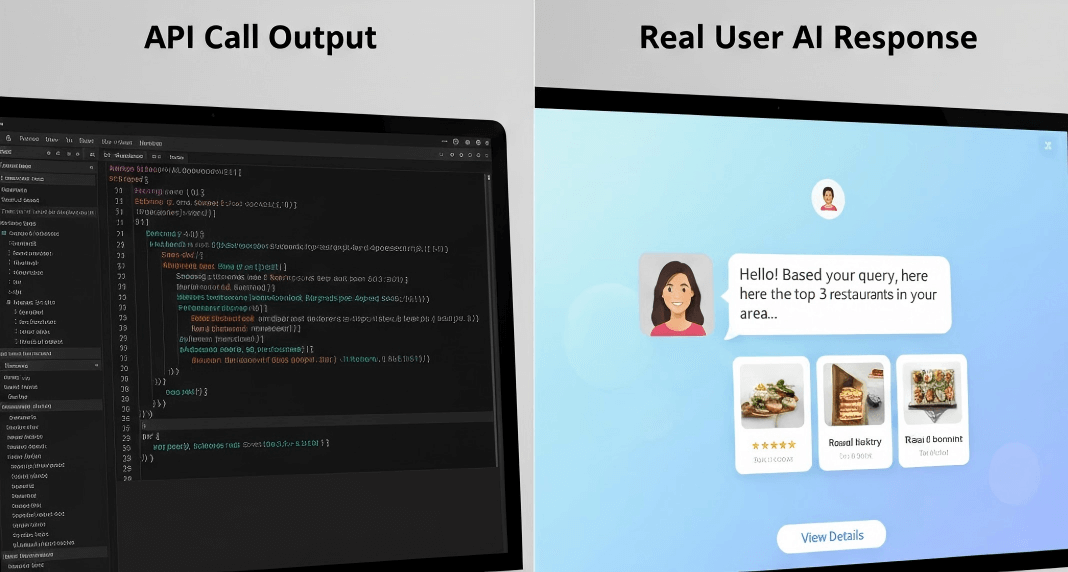
API 调用得到的是什么?是一个在特定条件下、由模型直接返回的文本结果。这个过程本身是确定的、可重复的、可规模化的,这也是它在工程上非常“友好”的原因。
但真实用户并不是通过 API 在使用 AI。真实用户面对的是一个被多重变量包围的系统:模型版本是否一致、是否叠加了系统级提示、是否引入个性化偏好、是否结合了实时搜索、是否受地理位置影响,这些因素都会直接改变最终输出。
也正因为如此,API 世界往往显得异常“干净”。它没有噪音,没有漂移,没有偶发性,结果高度可预测。而真实世界恰恰相反。你会看到同一个问题在不同时间引用不同来源;你会发现昨天还能被推荐的品牌,今天就被替换;你甚至会发现问题表述只改了一个词,答案结构就完全变了。
如果一个 GEO 监测体系主要建立在 API 数据之上,那么它并不是“不够精确”,而是在监测一个与现实世界并不等价的对象。
三、真正接近真实的监测,难度远高于大多数人的预期
很多人低估了“模拟真实用户”这件事的技术复杂度。从表面看,它似乎只是“不用 API,改用浏览器访问”。
但真正做过的人都知道,问题远不止如此。首先,生成式 AI 的输出本身具有高度漂移性。这意味着单次采样是没有意义的,少量样本得出的结论往往只是偶然结果。要判断一个品牌是否真的被 AI 稳定认知,你必须做的是长期、多轮、多维度的观察,而不是截图式验证。
其次,AI 理解世界的方式,和关键词时代完全不同。它并不是在匹配字符串,而是在构建“实体认知”。品牌是否被推荐,往往取决于它在整个信息网络中的一致性、可信度和关联结构,而不是某一个页面写得好不好。
这也是为什么很多团队在内容层面已经做了大量工作,却始终无法理解:为什么 AI 依然对自己“反应冷淡”。问题往往不在内容数量,而在信息结构是否对机器友好,是否存在认知冲突,是否在关键节点缺失可信信号。
最后,还有一个被严重低估的难点:真实用户行为本身就是不稳定的。
你必须接受这样一个事实:如果你真的在看“真人世界”,那你看到的结果一定是波动的、不完美的、甚至有时让人不安的。而很多工具为了“好卖”,恰恰选择了回避这种不确定性。
四、模拟真实访问:一场关于“数字拟态”的军备竞赛
想要看到真相,唯一的路就是模拟真实用户。但这太难了,难到绝大多数公司只能望而却步。
为了突破这一瓶颈,我们的系统目前正在全力攻克“真人模拟”技术,试图在服务器端构建一个个“幽灵用户”。这背后的技术难度主要体现在三个维度:
1. 跨越“恐怖谷”的拟人交互
现在的 AI 平台都有极强的反爬检测(如 Cloudflare)。如果你的监测程序打字速度太匀速、鼠标移动是直线,瞬间就会被拦截。
- 我们必须模拟人类思考时的随机延迟,甚至是打错字再删除的过程。
- 鼠标轨迹必须符合贝塞尔曲线,带有加速度和过冲感。
- 甚至要模拟人类阅读时的滚动和悬停,因为很多 AI 引用卡片只有在鼠标悬停时才会触发加载。
2. 全球住宅 IP 的“合法身份”
如果请求都来自数据中心,AI 会立刻封锁。
- 我们通过全球住宅代理网络,让每一次监测都伪装成“住在伦敦的 iPhone 用户”或“住在东京的安卓用户”。
- 只有这样,才能捕捉到因地理位置不同而产生的“地理漂移”现象,看到当地用户真正看到的答案。
3. 浏览器指纹的深度对抗
现代反爬系统会检查显卡渲染、音频硬件、甚至字体列表等数字指纹。
- 普通的自动化工具因为没有声卡显卡,一眼就会被识破。
- 我们需要在 WebGL 渲染中注入微小噪点,重写底层对象,确保在网络层看起来与真实的 Chrome 浏览器完全一致 。
结语:GEO 不是缺工具,而是缺对“真实”的敬畏
现在的 GEO 行业,正在经历一个很典型的阶段:
技术名词跑在认知前面,工具跑在理解前面。
很多所谓的问题,并不是“算法不行”或“内容没用”,而是从一开始,大家就在用一套并不等价的数据,试图解释一个真实而复杂的 AI 世界。
如果你做 GEO 的目标,是让品牌在真实用户面前被真实推荐,那么你迟早要面对一个事实:
不稳定,才是正常;解释不清,才是线索;而过度确定,往往意味着你被隔离在真实世界之外。

